







Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Los mejores documentos en venta realizados por estudiantes que han terminado sus estudios
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Descubre las mejores universidades de tu país según los usuarios de Docsity
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
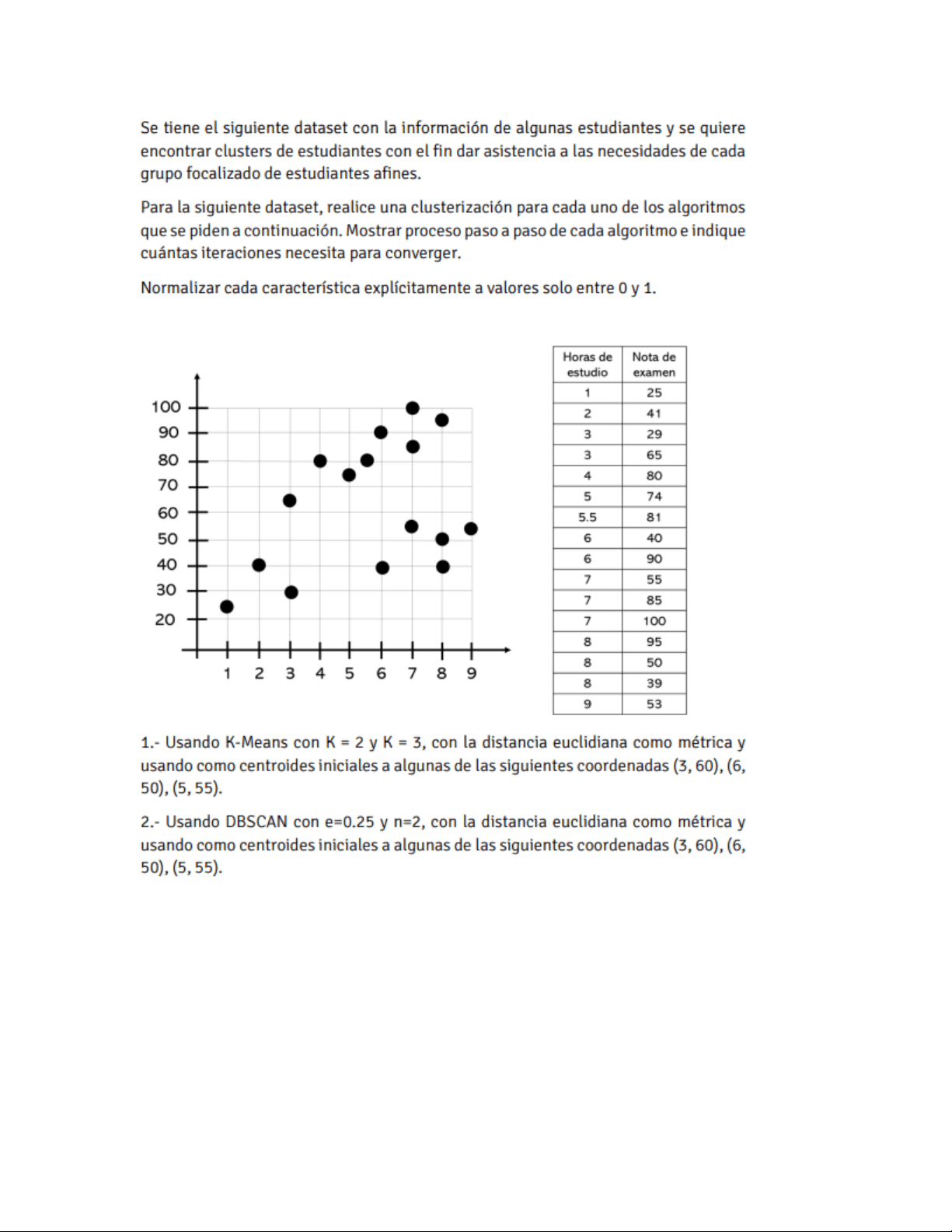
Ejercicios de Clusterizacion en Aprendizaje no supervisado
Tipo: Ejercicios
1 / 11

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Iniciamos normalizando las caracteristicas a 0 y 1 Primero identificamos el valor mínimo y máximo de cada columna Luego empleando la siguiente formula en toda la tabla, por cada uno de los valores: (valor – mínimo) / (máximo – mínimo) Esta formula se aplica en cada columna individualmente, proporcionando los siguientes valores: Ahora comenzaremos con:
Como no obtenemos los mismo clusters, volvemos a hacer otra iteración
Como no obtenemos los mismos clusters, hacemos otra iteración
Hacemos la segunda iteración para comprobar si se parecen
Como no se parecen, continuamos
Calculamos la distancia euclidiana de cada uno de los valores, comparándolos con sus vecinos de la siguiente forma, debemos de obtener un total de 16 de las siguientes tablas En base a los True que obtenemos, hacemos un conteo, y esos serian los vecinos que tendrían
Filtramos por aquellos que son mayores o iguales que 2, esos serian nuestros puntos núcleos, los que usaremos, los que son menores no nos funcionan Finalmente, obtenemos los puntos núcleos, y ahora debemos de revisar en cada lista, si ese vecino ese punto núcleo lo visita, y así se va formando un cluster, hacemos lo mismo por cada uno, quedando de la siguiente manera: Ahora simplemente quedaría, traducir las coordenadas y ya finalizamos nuestro trabajo identificando los valores que pertenecen a cada clusters