


Part 5: Finite Sample Properties
5-1/57
Econometrics I
Professor William Greene
Stern School of Business
Department of Economics

















































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
Restricted residuals in multiple linear regression
Typology: Lecture notes
1 / 57

This page cannot be seen from the preview
Don't miss anything!
German Health Care Usage Data, 7,293 Individuals, Varying Numbers of Periods
Data downloaded from Journal of Applied Econometrics Archive. There are altogether 27,326 observations. The number of observations ranges from 1 to 7.
(Frequencies are: 1=1525, 2=2158, 3=825, 4=926, 5=1051, 6=1000, 7=987).
Variables in the file are
DOCVIS = number of doctor visits in last three months HOSPVIS = number of hospital visits in last calendar year DOCTOR = 1(Number of doctor visits > 0) HOSPITAL = 1(Number of hospital visits > 0) HSAT = health satisfaction, coded 0 (low) - 10 (high) PUBLIC = insured in public health insurance = 1; otherwise = 0 ADDON = insured by add-on insurance = 1; otherswise = 0 HHNINC = household nominal monthly net income in German marks / 10000. (4 observations with income=0 were dropped) HHKIDS = children under age 16 in the household = 1; otherwise = 0 EDUC = years of schooling AGE = age in years MARRIED = marital status
For now, treat this sample as if it were a cross section, and as if it were the full population.
-1X |X ]
= + ( X X ) -1X E[ |X ]
= + 0
E[ b ] = E X {E[ b | X ]}
= E[ b ].
(The law of iterated expectations.)
Two sets of variables. What if the regression is computed without the second set of
variables?
What is the expectation of the "short" regression estimator? E[ b 1|( y = X 1 1 + X 2 2 +
)]
b 1 = ( X1 X1 )
-1 X 1 y
0 1
If you regress Quantity on Price and leave out Income. What do you get?
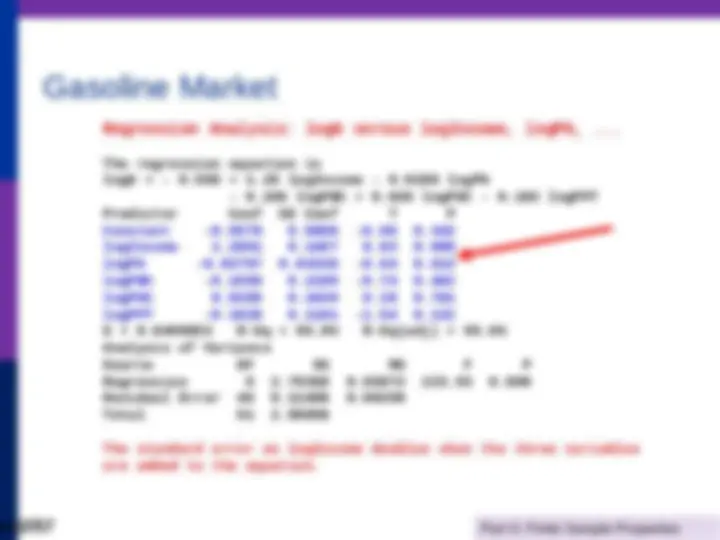
----------------------------------------------------------------------
Ordinary least squares regression ............
LHS=G Mean = 226. Standard deviation = 50. Number of observs. = 36
Model size Parameters = 3
Degrees of freedom = 33 Residuals Sum of squares = 1472.
Standard error of e = 6.
Fit R-squared =.
Adjusted R-squared =.
Model test F[ 2, 33] (prob) = 987.1(.0000) --------+-------------------------------------------------------------
Variable| Coefficient Standard Error t-ratio P[|T|>t] Mean of X
--------+-------------------------------------------------------------
Constant| -79.7535* 8.67255 -9.196. Y| .03692*** .00132 28.022 .0000 9232. PG| -15.1224*** 1.88034 -8.042 .0000 2.**
--------+-------------------------------------------------------------